Reminder
Even the simplest value in python is a complex object.
If we create an integer, we are instantiating an object of type int.
This gives us access to a lot of magic.
a = 1
| pyObject | |
|---|---|
| id | 0x7fa8655e00f0 |
| type | <class 'int'> |
| value | 1 |
| refs | 1 |
The memory allocated to our objects is managed for us by the python interpreter. Objects will be cleared from memory once they are no longer accessible to our programme. This is achieved by counting references.
Reference counting
a = "hello"
b = a
Reference counting
a = "hello"
b = a
a = "world"
A new pyObject is created at location 0x7f3b40d83f70 containing the string 'world'.
The variable a points to the new object.
The variable b still points to the original object.
Reference counting
a = "hello"
b = a
a = "world"
b = "world"
The pyObject at 0x7f3b40df00f0, containing the string 'hello' no longer has any references.
It will be identified by the garbage collector and the memory will be freed for use.
Reference counting implementation detail
Simple objects like Boolean values and smaller integers are automatically reused and are not garbage collected.
id(100)
id(100)
These would be expected to generate different identifiers. Each statement should create a value in memory, return it’s location, and immediately set the reference count to zero.
140397168938320
140397168938320
We get the same identifier, indicating that the same location in memory was used for both objects, even though no variable was created referencing the object.
This is an implementation detail and should not be relied upon in code.
Reference counting implementation detail
If we create larger objects, the behaviour is as expected. They will be created on demand and destroyed quickly.
id(1000000000)
id(1000000000)
Each statement creates a separate object in memory, which is discarded immediately.
140397166989520
140397166989936
The numbers are different, this is what you should be assuming. Data in memory are erased very quickly once no longer referenced.
Machine code and byte code
Code is a form of data too. Once compiled, instructions can be reduced to machine code. The CPU manages the flow through the sequence of instructions by incrementing a counter. Some instructions can be used to change the counter value.
In interpreted languages like python, the interpreter consumes byte code. Every python programme is compiled to bytecode, we will look at a few examples to get a sense of what is going on.
def conditional_return(a):
if a:
return "some value"
OPCODE OPNAME ARG ARGVAL
0 124 LOAD_FAST 0 a
2 114 POP_JUMP_IF_FALSE 4 8
4 100 LOAD_CONST 1 some value
6 83 RETURN_VALUE None None
8 100 LOAD_CONST 0 None
10 83 RETURN_VALUE None None
A function that does nothing
Here’s a function that does nothing.
the
passdoes nothing but syntactically it is necessary to avoid anIndentationError
def nothing():
pass
…and the resulting byte code.
OPCODE OPERATION ARGUMENT
0 100 LOAD_CONST None
2 83 RETURN_VALUE
This loads None and returns it.
Functions always return a value and they will return None by default.
Returning a value
Here we add a return statement.
def return_something():
return "some value"
…and the resulting byte code.
OPCODE OPERATION ARGUMENT
0 100 LOAD_CONST 'some value'
2 83 RETURN_VALUE
Simple, the bytecode loads our value (a literal, so its constant) and returns it.
Assignment
Here’s something a bit more advanced (!).
def assign():
a = 1
…and the resulting byte code.
OPCODE OPERATION ARGUMENT
0 100 LOAD_CONST 1
2 125 STORE_FAST a
4 100 LOAD_CONST None
6 83 RETURN_VALUE
It loads the constant (literal), 1 and stores it in variable a.
It then loads None and returns it.
Returning the value
This function does a tiny bit more, it returns the value of a.
def assign_and_return():
a = 1
return a
…and the resulting byte code.
OPCODE OPERATION ARGUMENT
0 100 LOAD_CONST 1
2 125 STORE_FAST a
4 124 LOAD_FAST a
6 83 RETURN_VALUE
We can see, the code does the same but it loads from a rather than loading None.
Returning an argument
This function receives a single argument and returns it.
def return_argument(a):
return a
…and the resulting byte code.
OPCODE OPERATION ARGUMENT
0 124 LOAD_FAST a
2 83 RETURN_VALUE
The variable a is already available.
So it just loads it and returns it.
Addition
What happens when we add numbers?
def return_argument_plus_one(a):
return a + 1
The byte code includes a new BINARY_ADD code.
OPCODE OPERATION ARGUMENT
0 124 LOAD_FAST a
2 100 LOAD_CONST 1
4 23 BINARY_ADD
6 83 RETURN_VALUE
We load the value a, load the constant 1, add them (presumably BINARY_ADD takes the two arguments) and return.
Multiple arguments
A similar example, with two arguments.
def return_argument_product_minus_one(a, b):
return a * b - 1
The resultant byte code loads the arguments a and b, multiplies them, loads the constant 1, subtracts it and returns the result.
OPCODE OPERATION ARGUMENT
0 124 LOAD_FAST a
2 124 LOAD_FAST b
4 20 BINARY_MULTIPLY
6 100 LOAD_CONST 1
8 24 BINARY_SUBTRACT
10 83 RETURN_VALUE
Conditionals
def conditional_return1(a, b):
if a:
return a
else:
return b
The byte code loads a and then includes a POP_JUMP_IF_FALSE code which will jump to code 8 if the loaded value (i.e. a) is False.
There are two paths to a return code.
OPCODE OPERATION ARGUMENT
0 124 LOAD_FAST a
2 114 POP_JUMP_IF_FALSE to 8
4 124 LOAD_FAST a
6 83 RETURN_VALUE
8 124 LOAD_FAST b
10 83 RETURN_VALUE
More efficient?
Taking advantage of the or operator seems more efficient.
def conditional_return2(a, b):
return a or b
The byte code is clearly more efficient, using JUMP_IF_TRUE_OR_POP.
OPCODE OPERATION ARGUMENT
0 124 LOAD_FAST a
2 112 JUMP_IF_TRUE_OR_POP to 6
4 124 LOAD_FAST b
6 83 RETURN_VALUE
Looping
A simple while loop decrements a until it’s less than 10.
This leads to some moderately complex byte code.
def looping1(a):
while a > 10:
a -= 1
return a
OPCODE OPERATION ARGUMENT
0 124 LOAD_FAST a
2 100 LOAD_CONST 10
4 107 COMPARE_OP >
6 114 POP_JUMP_IF_FALSE to 24
8 124 LOAD_FAST a
10 100 LOAD_CONST 1
12 56 INPLACE_SUBTRACT
14 125 STORE_FAST a
16 124 LOAD_FAST a
18 100 LOAD_CONST 10
20 107 COMPARE_OP >
22 115 POP_JUMP_IF_TRUE to 8
24 124 LOAD_FAST a
26 83 RETURN_VALUE
Alternative loop
A slightly different approach produces slightly different bytecode to achieve the same result.
def looping2(a):
while True:
if a <= 10:
return a
a -= 1
OPCODE OPERATION ARGUMENT
0 9 NOP
2 124 LOAD_FAST a
4 100 LOAD_CONST 10
6 107 COMPARE_OP <=
8 114 POP_JUMP_IF_FALSE to 14
10 124 LOAD_FAST a
12 83 RETURN_VALUE
14 124 LOAD_FAST a
16 100 LOAD_CONST 1
18 56 INPLACE_SUBTRACT
20 125 STORE_FAST a
22 113 JUMP_ABSOLUTE to 2
Accessing data over HTTP
This week we will look at getting data over HTTP.
The urllib.request module allows us to trigger HTTP requests.
This allows us to grab files from web servers.
from urllib.request import urlopen
url = 'http://gamr1520.github.io/GAMR1520/exercises/2.1.html'
response = urlopen(url)
data = response.read().decode('utf-8')
print(data[:95])
<!DOCTYPE html>
<html lang="en">
<head>
<title>Files and folders</title>
<meta charset="utf-8">
TBH, I usually use the third-party requests library for anything but the simplest examples. But
urllibworks perfectly for simple requests.
JSON APIs
Using the same approach and the json module, we can load data from JSON apis.
For example swapi.
import json
from urllib.request import urlopen
url = 'https://swapi.py4e.com/api/'
response = urlopen(url)
data = json.loads(response.read().decode('utf-8'))
print(json.dumps(data, indent=2))
{
"people": "https://swapi.py4e.com/api/people/",
"planets": "https://swapi.py4e.com/api/planets/",
"films": "https://swapi.py4e.com/api/films/",
"species": "https://swapi.py4e.com/api/species/",
"vehicles": "https://swapi.py4e.com/api/vehicles/",
"starships": "https://swapi.py4e.com/api/starships/"
}
Graphical user interfaces
import tkinter as tk
class MyApplication(tk.Tk):
def __init__(self):
super().__init__()
self.title('My Application')
self.intro1 = tk.Label(text="This is just some text", font=('Helvetica', 18))
self.intro2 = tk.Label(text="and some more", font=('Helvetica', 12))
self.intro1.grid(pady=(20, 0), padx=50)
self.intro2.grid(pady=(0, 20))
app = MyApplication()
app.mainloop()
Complex interfaces and custom widgets
We will build up to a fairly complex interface.
Phase test this week
The phase test will cover all the stuff we’ve looked at in the first two weeks
- Basic python syntax
- literals
- operators
- variables
- Built-in functions
print,inputetc.bool,int,listetc.
- Compound statements
- conditionals
- loops
- etc
- Functions
- positional arguments
- keyword arguments
returnstatements- etc.
- Compound data types
- tuples
- lists
- dicts
- sets
- Other stuff
- list comprehensions
- f-strings
- errors
You will be asked to read simple programmes and understand them.
- 60 minutes
- 25 questions
- Automatically marked
- Maximum 200 points
- Contributes 20% towards module mark
Last years phase test results
The phase test is a small component and is intended to test your basic grasp of the foundational concepts we have been looking at so far. Last year the vast majority of students had no problem with it.
- 57 submissions and 4 non-submissions (marked at 0%).
- 55 students achieved >40%, 43 >50%, 28 >60%, 15 >70%
- Mean score of 60%, maximum of 94%
You will have no problems as long as you are engaging with the materials and asking questions until you understand.
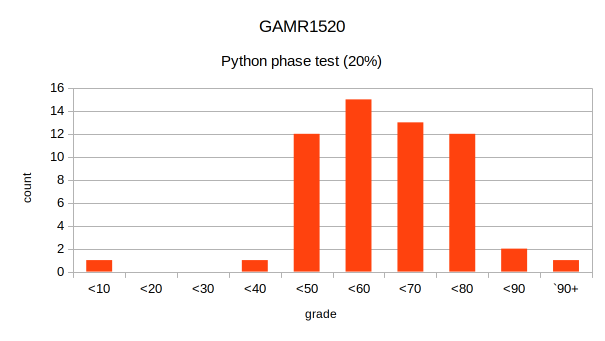
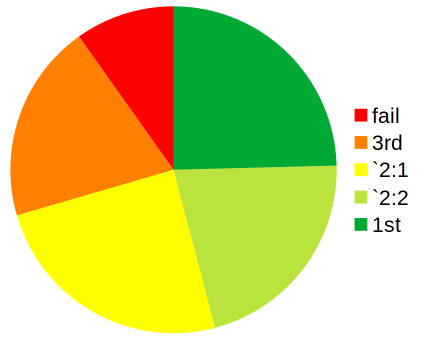
Make sure you understand this
def formatted_list(items, title="list", ch='*', pad=4):
width = max([len(i) for i in items + [title]]) + pad
hline = ch * width
result = [hline, title, hline] + items + [hline]
result = [f"{ch}{i.center(width)}{ch}" for i in result]
return "\n".join(result)
shopping = ['apples', 'bananas', 'cherries']
formatted_shopping = formatted_list(shopping, title='fruit', pad=8)
print(formatted_shopping)
******************
* fruit *
******************
* apples *
* bananas *
* cherries *
******************